문제 출처 : https://www.acmicpc.net/problem/1987
문제 설명
세로 R칸, 가로 C칸으로 된 표 모양의 보드가 있다. 보드의 각 칸에는 대문자 알파벳이 하나씩 적혀 있고, 좌측 상단 칸 (1행 1열) 에는 말이 놓여 있다.
말은 상하좌우로 인접한 네 칸 중의 한 칸으로 이동할 수 있는데, 새로 이동한 칸에 적혀 있는 알파벳은 지금까지 지나온 모든 칸에 적혀 있는 알파벳과는 달라야 한다. 즉, 같은 알파벳이 적힌 칸을 두 번 지날 수 없다.
좌측 상단에서 시작해서, 말이 최대한 몇 칸을 지날 수 있는지를 구하는 프로그램을 작성하시오. 말이 지나는 칸은 좌측 상단의 칸도 포함된다.
입력
첫째 줄에 R과 C가 빈칸을 사이에 두고 주어진다. (1 ≤ R,C ≤ 20) 둘째 줄부터 R개의 줄에 걸쳐서 보드에 적혀 있는 C개의 대문자 알파벳들이 빈칸 없이 주어진다.
출력
첫째 줄에 말이 지날 수 있는 최대의 칸 수를 출력한다.
문제 풀이 :
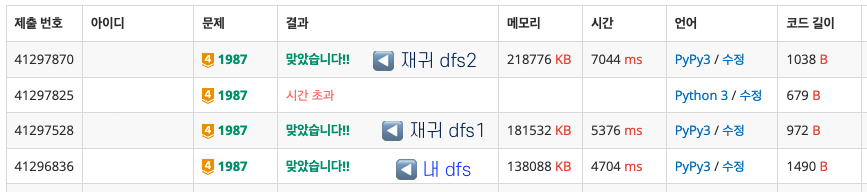
분명 문제 풀이법은 맞는 것 같은데 여러가지 조건 때문에 시간 초과가 났던 문제이다. bfs로 했을 때, deque를 사용하면 시간 초과가 뜬다. 따라서 bfs 탐색하고 있는 경로를 queue에 함께 넣고, set()을 이용해야 한다. set을 이용하면 중복되는 곳은 제거가 되기 때문에 시간을 훨씬 단축할 수 있다.
# bfs 사용
import sys
input = sys.stdin.readline
R, C = tuple(map(int, input().split()))
arr = []
for _ in range(R):
arr.append(list(input().rstrip()))
dx = [0, +1, 0, -1]
dy = [+1, 0, -1, 0]
A = ord('A')
alphabet = [0] * 26
alphabet[ord(arr[0][0]) - A] = 1
def bfs (R, C, board):
max_cnt = 0
que = set()
que.add((0, 0, arr[0][0]))
while que :
x, y, route = que.pop()
max_cnt = max(max_cnt, len(route))
for i in range(4):
temp_x = x + dx[i]
temp_y = y + dy[i]
if 0 <= temp_x < R and 0 <= temp_y < C:
if board[temp_x][temp_y] not in route:
que.add((temp_x, temp_y, route + board[temp_x][temp_y]))
return max_cnt
print(bfs(R, C, arr))다음으로 dfs 를 사용하는 방법인데, 답은 맞게 나오는 것 같은데 시간 초과가 나서 찾아보니 python3에서 dfs를 구현하면 이 문제는 시간 초과가 난다고 한다. 그래서 PyPy3를 사용하면 정답 처리 된다고 하는데, PyPy3를 사용해보는 것이 처음이라 PyPy3가 python이랑 뭐가 다른지 찾아보게 되었다. (참고: https://ralp0217.tistory.com/entry/Python3-와-PyPy3-차이)
결론적으로는 PyPy3를 사용하면 메모리를 좀 더 많이 사용하여 캐시에 자주 사용되는 코드를 저장해두어 실행 속도를 개선한다는 것이다. 그래서 간단한 코드를 작성할 때는 Python3를, 복잡한 코드를 작성할 때는 PyPy3를 이용하면 이점을 얻을 수 있다고 한다. (하지만 코딩테스트에서 사용되는 플랫폼이 PyPy3를 지원하지 않는 경우도 있으니, 웬만하면 Python을 사용하려고 한다.)
아무튼 dfs로 작성한 코드는 다음과 같다.
R, C = tuple(map(int, input().split()))
arr = []
for _ in range(R):
arr.append(list(input()))
def dfs (R, C, board):
visited = [0] * 26
max_cnt = 0
cnt, A = 0, ord('A')
visited[ord(board[0][0]) - A] = 1
stack = [(0, 0, 0, visited)] # stack을 이용한 dfs 활용
while stack :
x, y, count, visits = stack.pop()
if max_cnt < count :
max_cnt = count
if y > 0 :
visited = visits.copy()
left = ord(board[x][y-1])
if visited[left-A] == 0: # 왼쪽이 존재하는 경우
visited[left-A] = 1
stack.append((x, y-1, count + 1, visited))
if y < C-1 :
visited = visits.copy()
right = ord(board[x][y+1])
if visited[right - A] == 0: # 오른쪽이 존재하는 경우
visited[right-A] = 1
stack.append((x, y+1, count + 1, visited))
if x > 0 :
visited = visits.copy()
up = ord(board[x-1][y])
if visited[up-A] == 0: # 위쪽이 존재하는 경우
visited[up-A] = 1
stack.append((x-1, y, count + 1, visited))
if x < R-1 :
visited = visits.copy()
down = ord(board[x+1][y])
if visited[down-A] == 0: # 아래쪽이 존재하는 경우
visited[down-A] = 1
stack.append((x+1, y, count + 1, visited))
return max_cnt
print(dfs(R, C, arr)+1)가장 까다로운 건, 경로를 저장해두는 과정에서 해당 지점까지의 경로를 stack에 함께 저장해줘야 하는데 위, 아래, 왼쪽, 오른쪽을 다 탐색하다보니 자꾸 이 해당 지점까지의 경로를 저장해둔 리스트가 변한다는 것이었다. 그래서 현재 출발점의 경로를 두고, 위 쪽 노드를 스택에 넣을 때와 아래 쪽 노드를 스택에 넣을 때 각각 출발점의 경로를 복사해와서 수정했다. 사실 이 부분 때문에 시간이 오래 걸리지 않을까 고민했지만, 재귀를 사용하는 것보다는 훨씬 적은 시간이 걸렸다. (그래도 bfs를 사용한 것보다는 비교도 안되게 오래 걸리긴 했다)

'[알고리즘] 문제 풀이' 카테고리의 다른 글
| [동적 계획법] 프로그래머스 - 2 x n 타일링 (0) | 2022.04.01 |
|---|---|
| [재귀] 프로그래머스 - 하노이의 탑 (0) | 2022.04.01 |
| 프로그래머스 - 크레인 인형뽑기 (0) | 2021.11.06 |
| 프로그래머스 - 숫자 문자열과 영단어 (0) | 2021.11.06 |
| [해시] 프로그래머스 - 베스트앨범 (0) | 2021.11.06 |



댓글